 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgiPIX: Bridging Simulation and Reality in Indoor Aerial Inspection
Apr 09, 2026Autonomous indoor flight for critical asset inspection presents fundamental challenges in perception, planning, control, and learning. Despite rapid progress, there is still a lack of a compact, active-sensing, open-source platform that is reproducible across simulation and real-world operation. To address this gap, we present Agipix, a co-designed open hardware and software platform for indoor aerial autonomy and critical asset inspection. Agipix features a compact, hardware-synchronized active-sensing platform with onboard GPU-accelerated compute that is capable of agile flight; a containerized ROS~2-based modular autonomy stack; and a photorealistic digital twin of the hardware platform together with a reliable UI. These elements enable rapid iteration via zero-shot transfer of containerized autonomy components between simulation and real flights. We demonstrate trajectory tracking and exploration performance using onboard sensing in industrial indoor environments. All hardware designs, simulation assets, and containerized software are released openly together with documentation.
Data Scaling for Navigation in Unknown Environments
Jan 14, 2026Generalization of imitation-learned navigation policies to environments unseen in training remains a major challenge. We address this by conducting the first large-scale study of how data quantity and data diversity affect real-world generalization in end-to-end, map-free visual navigation. Using a curated 4,565-hour crowd-sourced dataset collected across 161 locations in 35 countries, we train policies for point goal navigation and evaluate their closed-loop control performance on sidewalk robots operating in four countries, covering 125 km of autonomous driving. Our results show that large-scale training data enables zero-shot navigation in unknown environments, approaching the performance of policies trained with environment-specific demonstrations. Critically, we find that data diversity is far more important than data quantity. Doubling the number of geographical locations in a training set decreases navigation errors by ~15%, while performance benefit from adding data from existing locations saturates with very little data. We also observe that, with noisy crowd-sourced data, simple regression-based models outperform generative and sequence-based architectures. We release our policies, evaluation setup and example videos on the project page.
Minimal Time Series Transformer
Mar 12, 2025



Transformer is the state-of-the-art model for many natural language processing, computer vision, and audio analysis problems. Transformer effectively combines information from the past input and output samples in auto-regressive manner so that each sample becomes aware of all inputs and outputs. In sequence-to-sequence (Seq2Seq) modeling, the transformer processed samples become effective in predicting the next output. Time series forecasting is a Seq2Seq problem. The original architecture is defined for discrete input and output sequence tokens, but to adopt it for time series, the model must be adapted for continuous data. This work introduces minimal adaptations to make the original transformer architecture suitable for continuous value time series data.
Introduction to Sequence Modeling with Transformers
Feb 26, 2025
Understanding the transformer architecture and its workings is essential for machine learning (ML) engineers. However, truly understanding the transformer architecture can be demanding, even if you have a solid background in machine learning or deep learning. The main working horse is attention, which yields to the transformer encoder-decoder structure. However, putting attention aside leaves several programming components that are easy to implement but whose role for the whole is unclear. These components are 'tokenization', 'embedding' ('un-embedding'), 'masking', 'positional encoding', and 'padding'. The focus of this work is on understanding them. To keep things simple, the understanding is built incrementally by adding components one by one, and after each step investigating what is doable and what is undoable with the current model. Simple sequences of zeros (0) and ones (1) are used to study the workings of each step.
DAVIDE: Depth-Aware Video Deblurring
Sep 02, 2024Video deblurring aims at recovering sharp details from a sequence of blurry frames. Despite the proliferation of depth sensors in mobile phones and the potential of depth information to guide deblurring, depth-aware deblurring has received only limited attention. In this work, we introduce the 'Depth-Aware VIdeo DEblurring' (DAVIDE) dataset to study the impact of depth information in video deblurring. The dataset comprises synchronized blurred, sharp, and depth videos. We investigate how the depth information should be injected into the existing deep RGB video deblurring models, and propose a strong baseline for depth-aware video deblurring. Our findings reveal the significance of depth information in video deblurring and provide insights into the use cases where depth cues are beneficial. In addition, our results demonstrate that while the depth improves deblurring performance, this effect diminishes when models are provided with a longer temporal context. Project page: https://germanftv.github.io/DAVIDE.github.io/ .
Probabilistic Subgoal Representations for Hierarchical Reinforcement learning
Jun 24, 2024



In goal-conditioned hierarchical reinforcement learning (HRL), a high-level policy specifies a subgoal for the low-level policy to reach. Effective HRL hinges on a suitable subgoal represen tation function, abstracting state space into latent subgoal space and inducing varied low-level behaviors. Existing methods adopt a subgoal representation that provides a deterministic mapping from state space to latent subgoal space. Instead, this paper utilizes Gaussian Processes (GPs) for the first probabilistic subgoal representation. Our method employs a GP prior on the latent subgoal space to learn a posterior distribution over the subgoal representation functions while exploiting the long-range correlation in the state space through learnable kernels. This enables an adaptive memory that integrates long-range subgoal information from prior planning steps allowing to cope with stochastic uncertainties. Furthermore, we propose a novel learning objective to facilitate the simultaneous learning of probabilistic subgoal representations and policies within a unified framework. In experiments, our approach outperforms state-of-the-art baselines in standard benchmarks but also in environments with stochastic elements and under diverse reward conditions. Additionally, our model shows promising capabilities in transferring low-level policies across different tasks.
PlaceNav: Topological Navigation through Place Recognition
Oct 05, 2023



Recent results suggest that splitting topological navigation into robot-independent and robot-specific components improves navigation performance by enabling the robot-independent part to be trained with data collected by different robot types. However, the navigation methods are still limited by the scarcity of suitable training data and suffer from poor computational scaling. In this work, we present PlaceNav, subdividing the robot-independent part into navigation-specific and generic computer vision components. We utilize visual place recognition for the subgoal selection of the topological navigation pipeline. This makes subgoal selection more efficient and enables leveraging large-scale datasets from non-robotics sources, increasing training data availability. Bayesian filtering, enabled by place recognition, further improves navigation performance by increasing the temporal consistency of subgoals. Our experimental results verify the design and the new model obtains a 76% higher success rate in indoor and 23% higher in outdoor navigation tasks with higher computational efficiency.
Depth-Aware Image Compositing Model for Parallax Camera Motion Blur
Mar 30, 2023Camera motion introduces spatially varying blur due to the depth changes in the 3D world. This work investigates scene configurations where such blur is produced under parallax camera motion. We present a simple, yet accurate, Image Compositing Blur (ICB) model for depth-dependent spatially varying blur. The (forward) model produces realistic motion blur from a single image, depth map, and camera trajectory. Furthermore, we utilize the ICB model, combined with a coordinate-based MLP, to learn a sharp neural representation from the blurred input. Experimental results are reported for synthetic and real examples. The results verify that the ICB forward model is computationally efficient and produces realistic blur, despite the lack of occlusion information. Additionally, our method for restoring a sharp representation proves to be a competitive approach for the deblurring task.
Seq2Seq Imitation Learning for Tactile Feedback-based Manipulation
Mar 05, 2023Robot control for tactile feedback-based manipulation can be difficult due to the modeling of physical contacts, partial observability of the environment, and noise in perception and control. This work focuses on solving partial observability of contact-rich manipulation tasks as a Sequence-to-Sequence (Seq2Seq)} Imitation Learning (IL) problem. The proposed Seq2Seq model produces a robot-environment interaction sequence to estimate the partially observable environment state variables. Then, the observed interaction sequence is transformed to a control sequence for the task itself. The proposed Seq2Seq IL for tactile feedback-based manipulation is experimentally validated on a door-open task in a simulated environment and a snap-on insertion task with a real robot. The model is able to learn both tasks from only 50 expert demonstrations, while state-of-the-art reinforcement learning and imitation learning methods fail.
A Simulation Benchmark for Vision-based Autonomous Navigation
Apr 01, 2022

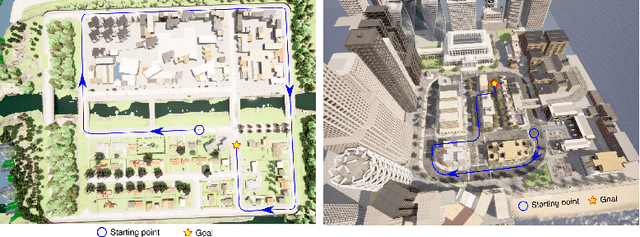
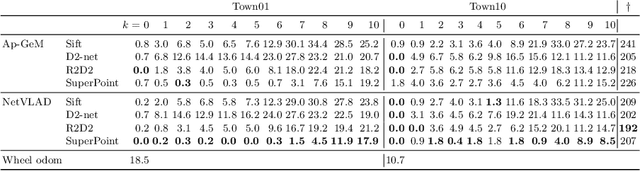
This work introduces a simulator benchmark for vision-based autonomous navigation. The simulator offers control over real world variables such as the environment, time of day, weather and traffic. The benchmark includes a modular integration of different components of a full autonomous visual navigation stack. In the experimental part of the paper, state-of-the-art visual localization methods are evaluated as a part of the stack in realistic navigation tasks. To the authors' best knowledge, the proposed benchmark is the first to study modern visual localization methods as part of a full autonomous visual navigation stack.